gatekeeper-controller-manager is leaking memory #2654
Comments
|
Heap Dump: one taken a few minutes after the start and one taken 3h later Goroutines stacktrace: |
|
Looking at the stacktrace, I think it's leaking connections (considering the growing number of |
|
Thank you for the detailed write up! How are you analyzing the heap dump? We tried opening it with but this yields an error: |
|
🤔 I just did that and it opened for me (I'm using |
|
Stack trace working for me. It definitely seems like there is a lot of space being used by http read/write buffers. Does the memory use increasing over time happen to the audit pod and the webhook pods, or just the webhook pods? |
|
I wonder if this is from external data creating multiple clients? From the golang docs:
Our code appears to create a new client for every request: @dethi does disabling calls to external data remove the leak? |
|
Interesting, maybe-on-topic finds. https://coder.com/blog/go-leak-mysteries Note that it does look like we're closing the response body. |
Only the webhook pods. The audit pod has stable memory usage.
We don't have any external configured and don't use external data at the moment, but I can try to disable it. |
|
Still leaking with external-data disabled. |
Can you please confirm the same feature flags used with older versions of Gatekeeper did not have this issue? |
|
|
|
Hey @dethi, We're still trying to chase down this leak, but could use a little more to go off. We noticed a lot of http calls in the heap dump. One theory is that event emitter could be leaking connections. To this end, could you try disabling admission events (set the flag We're also curious about the admission webhook's usage. Is this a relatively static cluster, where resource are not changed very frequently? Or is it more like a test cluster where resources are getting created and destroyed frequently (particularly namespaces)? If you have metrics set up, it would be helpful if could share the values/graphs for A couple other quick questions:
Thanks :) |
I will change that now and reports the result tomorrow!
Both. We see this same leak happening on all our clusters, dev and prod. dev clusters have a lot of churn (new namespace/deployment created at least every 10-15min). Prod cluster have relatively low churn (outside of a daily deploy and a cronjob that run every 5min).
Not using any mutation at the moment. I will disable it after the
No, we aren't using replicated data.
Yes we do :). Here is an example of what the metrics looks like on a prod cluster. Looking at the last 12h, pretty quiet. Happy to share more if you think it shows something interesting.
|
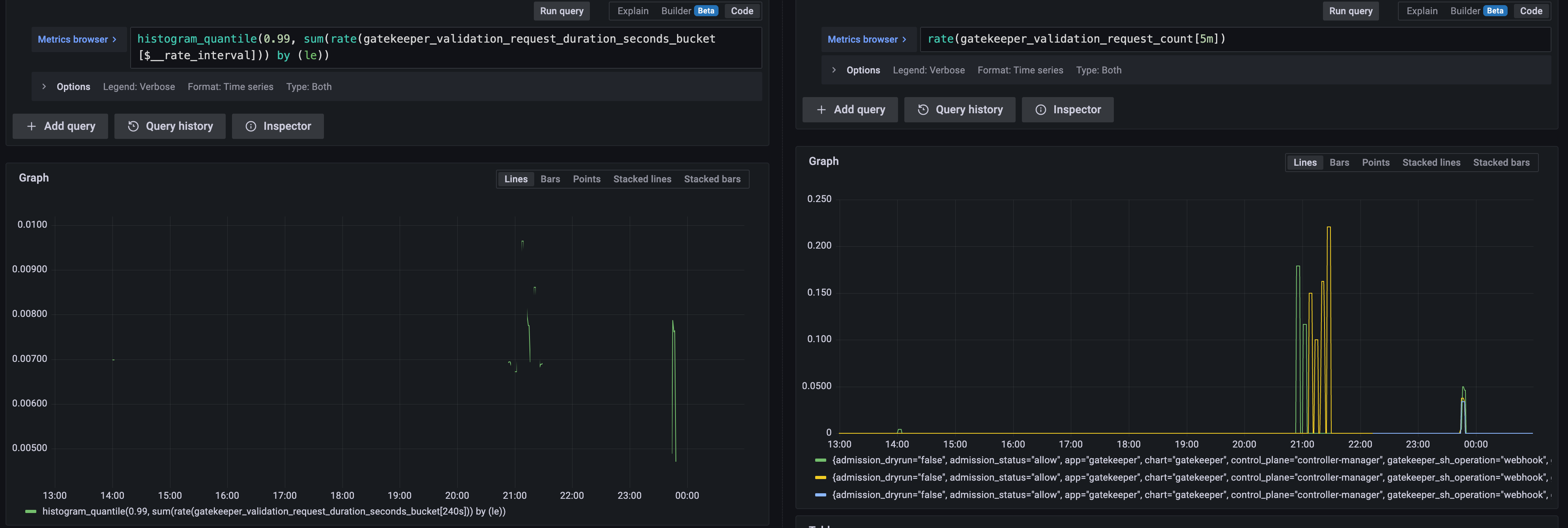
|
Tried both EDIT: both at the same time has the same effect: still leaking. |
|
One thing that I noticed in the logs, not sure if it's normal or not, but the controller seems to reconcile the constraint every ~10mins, even when there was no change to the constraint or constraint template.
|

|
Thank you for helping us gather data!
This could be due to a watch getting interrupted, though periodic re-reconciliation is expected in how controller-runtime works (I forget the default frequency). You mentioned the audit pod does not have this memory leak behavior. Is that still true? Does it also have these log messages? How many total constraints do you have on your cluster? Another explanation could be due to changes to ConstraintPodStatus resources: gatekeeper/pkg/controller/constraint/constraint_controller.go Lines 179 to 182 in 7c519b4 Or reconciling changes to the The weird thing is that if audit is unaffected, it should be something specific to the webhook process and not controllers, since the audit/status pods share the same controllers and watch the same resources. Double weird is that the webhook has fairly low activity, which would point against it being due to the webhook serving requests, which would point to controllers. If audit is still symptom-free, what flags does the audit pod have? If the audit pod has a |
Yes, audit pod doesn't have this memory leak. And yes, it is also logging
At the moment, only 3.
I will try that and come back to you! |
|
Still leaking memory with |
|
Can you share your rego? is the same rego/constraint template being used for both webhook and audit? |
|
Yes, both audit and the controller are using the exact same constraint and ConstraintTemplate. The 3 constraints use:
|
|
If you take a webhook pod and run another copy under a different name and with different labels (this ensures there will be zero webhook traffic since it's not part of the webhook service), does the memory leak still occur? |
|
Also curious how much memory the audit pod uses? |
|
The heap dump seems to show most memory usage associated with processing the webhook, which seems to jive with the theory that it's serving requests that's causing memory consumption. The zero-traffic test should confirm that's the right area of investigation. Assuming it is, the next step is why/how? Especially if the cluster is low-traffic. Do low traffic clusters leak at the same rate as clusters with higher Gatekeeper QPS? Does setting How much CPU does the webhook pod have? If <1, does increasing it to somewhere between 1-2 fix the issue? |
|
I have taken a new heap dump, when the memory was much higher (180MB), to show more clearly where the leak is coming from (
|

CPU req 100m, limit 1. They barely use anything at all.
Yes, they all leak at the same rate.
|


|
Thanks for the extra data! I'll take a look at the dump. Since there are a lot of potential places where HTTP connections can be initiated, I'm trying to narrow down what areas of code are the most likely candidates. Did you get a chance to run this test?
|
|
I missed that part. Trying it now, will report the result tomorrow! |
|
Here is the result of the webhook pods: still leaking even with no webhook being served.
Here is the new deployment I deployed: And confirmation that it wasn't targeted by the webhook: |

|
I think I found the origin of the leak using I'm gonna validate by first disabling it |
- The resp.Body was never closed, thus causing one connection to be leaked for each executions. - Creating a new transport based on the default transport, to inherit some of the default timeouts. Most importantly, this ensure that there is a default TLSHandshakeTimeout (10s) and dial timeout (30s). - Disable http keep alive, to avoid reuse of the same http connection. Otherwise, we may fail the healthcheck when the certs is rotated (new cert on disk wouldn't match the cert attached to the reused connection opened earlier). Fix open-policy-agent#2654
- The resp.Body was never closed, thus causing one connection to be leaked for each executions. - Creating a new transport based on the default transport, to inherit some of the default timeouts. Most importantly, this ensure that there is a default TLSHandshakeTimeout (10s) and dial timeout (30s). - Disable http keep alive, to avoid reuse of the same http connection. Otherwise, we may fail the healthcheck when the certs is rotated (new cert on disk wouldn't match the cert attached to the reused connection opened earlier). Fix open-policy-agent#2654
- The resp.Body was never closed, thus causing one connection to be leaked for each executions. - Creating a new transport based on the default transport, to inherit some of the default timeouts. Most importantly, this ensure that there is a default TLSHandshakeTimeout (10s) and dial timeout (30s). - Disable http keep alive, to avoid reuse of the same http connection. Otherwise, we may fail the healthcheck when the certs is rotated (new cert on disk wouldn't match the cert attached to the reused connection opened earlier). Fix open-policy-agent#2654 Signed-off-by: Thibault Deutsch <[email protected]>
|
That was indeed the origin of the leak. Submitted a fix! |
|
Thank you so much! What was the breadcrumb from netstat/kubectl debug that led you to the health check code? Only remaining inbound connection? |
I quickly glanced at the flags and saw |
|
Nice debugging! Thanks for sharing. |
- The resp.Body was never closed, thus causing one connection to be leaked for each executions. - Creating a new transport based on the default transport, to inherit some of the default timeouts. Most importantly, this ensure that there is a default TLSHandshakeTimeout (10s) and dial timeout (30s). - Disable http keep alive, to avoid reuse of the same http connection. Otherwise, we may fail the healthcheck when the certs is rotated (new cert on disk wouldn't match the cert attached to the reused connection opened earlier). Fix open-policy-agent#2654 Signed-off-by: Thibault Deutsch <[email protected]>
- The resp.Body was never closed, thus causing one connection to be leaked for each executions. - Creating a new transport based on the default transport, to inherit some of the default timeouts. Most importantly, this ensure that there is a default TLSHandshakeTimeout (10s) and dial timeout (30s). - Disable http keep alive, to avoid reuse of the same http connection. Otherwise, we may fail the healthcheck when the certs is rotated (new cert on disk wouldn't match the cert attached to the reused connection opened earlier). Fix open-policy-agent#2654 Signed-off-by: Thibault Deutsch <[email protected]>
Uh oh!
There was an error while loading. Please reload this page.
What steps did you take and what happened:
On all our GKE clusters,
gatekeeper-controller-managerget OOM Killed once every ~24-30h. You can see on the screenshot below that the memory keep increasing over time, which indicate to me that there is a memory leak somewhere.I just enabled pprof, I will add heap profile as soon as I have them
What did you expect to happen:
Memory usage to be stable over time.
Anything else you would like to add:
This was already happening on the previous version we were running,
openpolicyagent/gatekeeper:v3.10.0-beta.0Environment:
openpolicyagent/gatekeeper:v3.11.0kubectl version):v1.23.14-gke.1800gatekeeper-controller-manager:The text was updated successfully, but these errors were encountered: